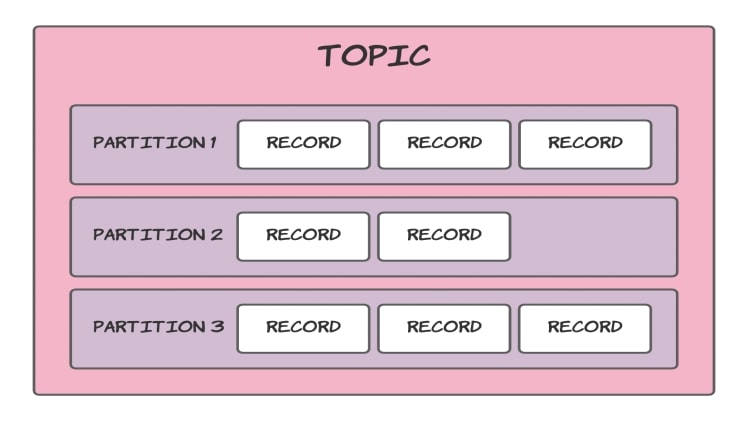
Apache Kafka is a widely-used Open Source and Distributed event-streaming platform. It provides a service for the real-time sending & receiving of data between processes, servers, and applications. For storing events and messages in a logical order, Kafka provides a fundamental unit called Topics. Each of the Kafka Topics consists of one or more Kafka partitions. While creating a Kafka topic, you need to specify a unique name, the number of partitions, replication factor, and data retention duration. To optimally design a Kafka Topic that caters to your requirements, you can follow a set of guidelines discussed below.
Best Strategies for Creating a Kafka Topic
When creating a Kafka Topic, there is no single strategy to optimally configure your Kafka Topic parameters. However, you can decide on a strategy based on the following aspects that suit your business needs and provide the best possible solution:
- Higher Throughput
- Improved Latency
- Better Availability
- Necessary Ordering
- Multiple Event Types in a Single Kafka Topic
- Records without Keys
1. Higher Throughput
Apache Kafka provides an efficient platform by performing writes to different partitions in parallel on both the producer side and the broker side. In turn, this allows expensive operations like compression to take place by effectively consuming more hardware resources. It is to be noted that Apache Kafka passes data from a single partition to a consumer thread. Thus, the higher the number of partitions in a cluster the higher the throughput.
Considering Throughput as your performance factor, you can select an estimated number of partitions based on a rough formula. For instance, assume that t is your desired throughput on a single partition for production p and consumption c. For achieving this, you need to have at least max(t/p, t/c) partitions.
However, too many partitions can also be problematic from the Producer’s perspective. A producer has an upper limit set for its memory for buffering incoming messages. After enough data is queued in the buffer, it is then passed on to the broker. More partitions mean more memory required for the Producer than the configured limit. Hence, for a good throughput, it is recommended to allocate at least a few 10s of KB per partition being produced in the producer. Later, you can also configure the total amount of memory when the number of partitions increases significantly.
2. Improved Latency
Kafka’s end-to-end latency is defined by the time between the producer publishing the message and the consumer reading the message. Kafka publishes the message to the consumer only after the message is replicated in all other replicas. Hence, the time taken in the replications contributes significantly to end-to-end latency. Owing to its Architecture, Kafka broker uses a single thread to carry out the replication for all the partitions with another broker. Therefore, too many partitions may cause a significant delay. Keeping Latency in focus, you can limit the number of partitions per broker to 100 x b x r. Here, b represents the number of brokers in a Kafka cluster and r is the value of the replication factor.
3. Better Availability
Taking complete care of your data, Kafka replicates your data providing high availability & durability. According to the replication factor set by you, a partition can have several replicas stored in different brokers. All the replicas are automatically managed & kept in sync by Kafka. The recommended value for the replication factor is 3. For better availability, it is also a good practice to set the “min.insync.replicas” to “all”. This ensures that a new message written is replicated to all the replicas else the message will be considered a fail.
Kafka selects a replica as a leader and the rest are termed as followers. In case of a broker failure, Kafka shifts the leader of these temporarily unavailable partitions to other replicas. This generally takes in only a few milliseconds. Although, if the broker is closed uncleanly, the duration of the unavailability becomes directly related to the number of partitions. Though this type of failure is rare, you can improve the availability by setting the number of partitions per broker to 2000-4000 and the net number of partitions in the cluster to low 10,000s.
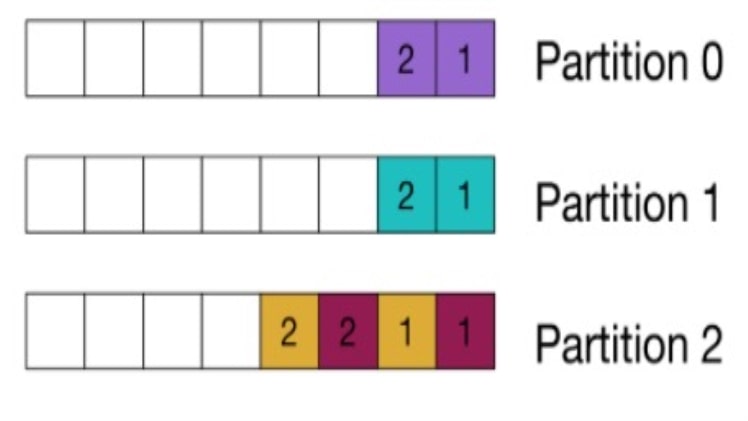
4. Necessary Ordering
In many cases, the order of the events is important when dealing with the same entity. The order of the events is especially relevant when using the event sourcing approach for data modeling. Here, the states of the aggregated objects are derived from the event log by playing them in a specific order. Therefore, there can be different types of events, but all the events that define the aggregate must belong to the same Kafka topic. For example, you can use the customer ID as a partitioning key to maintaining the order by sending all the events to the same Kafka topic.
5. Multiple Event Types in a Single KafkaTopic
The Avro-based Kafka Schema Registry can be used to handle multiple event types in a single Kafka topic. This schema-based encoding assumes that there is only one schema for each Kafka Topic. It allows for registering new versions of the schema and verifies if the schema changes are backward & forward compatible. All the schemas are registered by a subject name. This subject is the <topic>-key for message keys and <topic>-value for message values. Using this, you can effortlessly place all the different events for a particular entity in the same topic.
6. Records without Keys
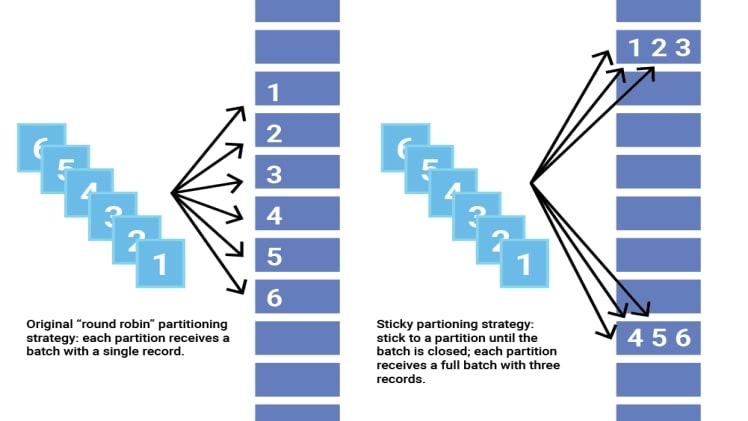
When multiple records need to be sent to a partition, Kafka sends them in batches. To simplify the process of batch forming, Kafka provides a Partitioner class that assigns the partition for each record. Generally, Kafka hashes the key of a record to get the partition. However, there are records without keys. For them, you can use Kafka’s Sticky Partitioning Strategy. It spreads out these records into smaller batches by picking a single partition to send all non-keyed records. After a batch at the partition is full, the sticky partitioner randomly selects a new partition. Thus, as compared to the traditional inefficient method of handling these types of records, the Sticky partitioning strategy provides a lower latency.
Conclusion
In this article, you have learned how to effectively create a Kafka Topic. Higher Throughput, Low Latency, and improved data availability are the most sought-after performance goals while working with Apache Kafka. You can achieve all this by optimally setting the number of partitions and the replication factor. For cases that require you to send multiple items to a single Kafka topic, you can use features provided by the Kafka Schema Registry. Another popular situation is dealing with records that are without partitioning keys. You can use the Sticky partitioning strategy for them and promote a lower latency.

